Translated Language Model (T-LM) enables businesses creating content in languages other than English to fully leverage the text generation capabilities of GPT-4. The service addresses the performance and cost disparity associated with using GPT-4 in languages other than English, enabling companies to create and restructure content in 200 languages.
T-LM enhances GPT-4's top-notch performance in 200 languages
T-LM assists content creators in generating and restructuring content in 200 languages. T-LM enables chatbots and support systems to operate smoothly in the user's language. T-LM helps users generate content on multilingual platforms in their native language Every other use case of GPT-4 with prompts in languages other than English.Assisting global content
creation teamsEnhancing multilingual
customer supportFacilitating user-generated content
creation on global platforms
Why T-LM
Until now, GPT's impressive performance has been a privilege of the English-speaking world. Companies operating in languages other than English have often found their performance lagging behind that of GPT models from several years ago, with some languages trailing by as much as three years. For these companies, the performance gap in understanding, generating, and restructuring content in languages other than English was an ongoing challenge that often prevented them from taking full advantage of generative AI.

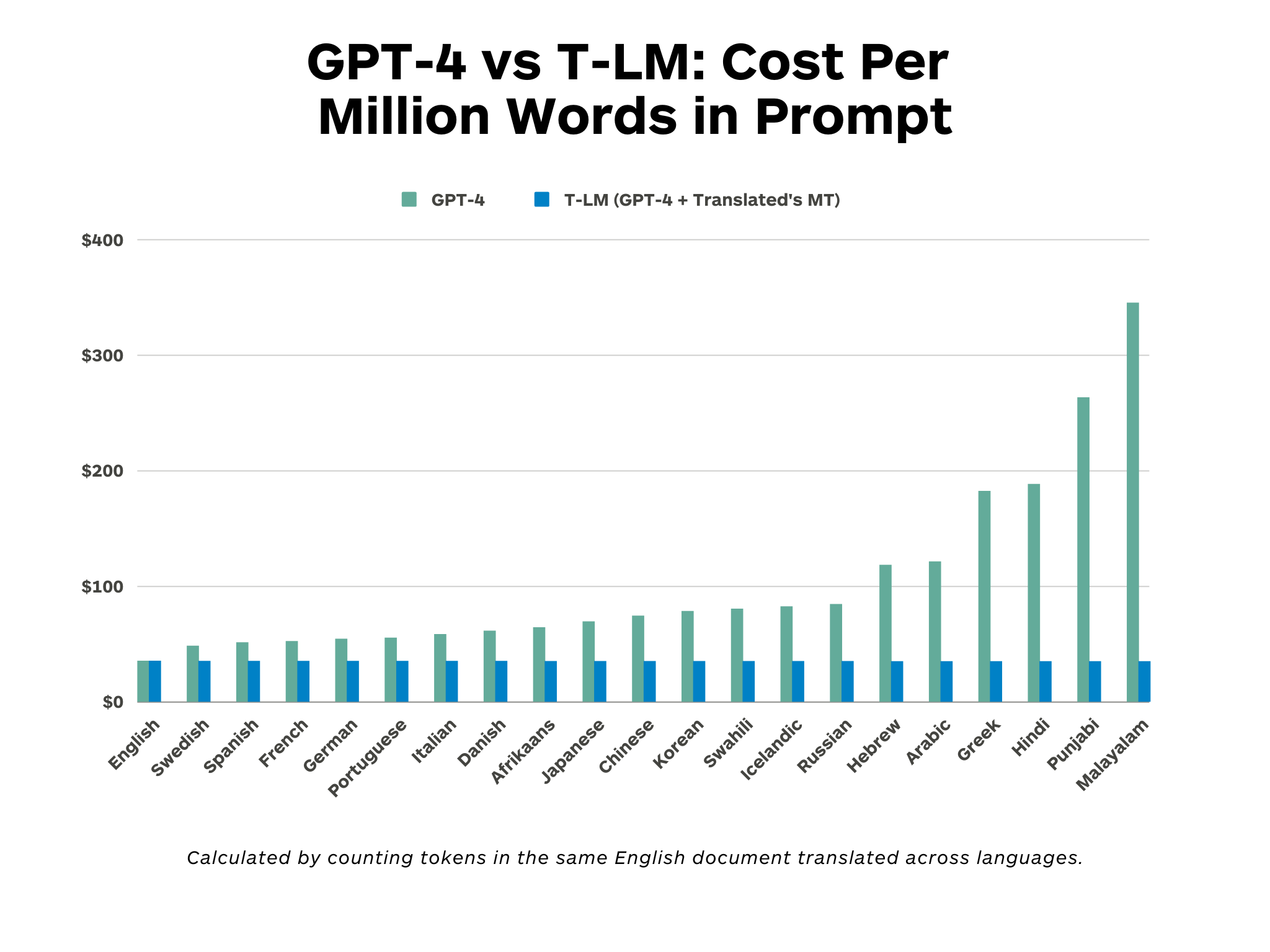
Additionally, using GPT-4 in languages other than English can cost up to 15 times more because the pricing model is based on text segmentation (tokenization) that is optimized for English.
How T-LM works
The disparity in GPT-4’s performance between English and other languages arises from the predominance of English-centric sources – such as the Common Crawl dataset and Wikipedia – in training data, leading to inferior outcomes in languages other than English. T-LM addresses this disparity by translating the initial prompt from the source language to English then back to the user's language using a specialized model of ModernMT.
Clients can optionally use their existing ModernMT keys to employ adaptive models within GPT-4. At no additional cost, they can also submit reference materials like website content, knowledge bases, or brand guidelines to adapt both the MT and language model components.
This approach also lowers the cost of using GPT-4 by reducing the number of token required to process the prompts.
Acehnese - Afrikaans - Akan - Albanian - Amharic - Arabic - Armenian - Assamese - Asturian - Awadhi - Ayacucho Quechua - Aymara, Central - Azerbaijani - Azerbaijani, Northern - Azerbaijani, Southern - Balinese - Bambara - Banjar - Bashkir - Belarusian - Bemba - Bengali - Bhojpuri - Bosnian - Buginese - Bulgarian - Catalan - Cebuano - Chhattisgarhi - Chinese (Simplified) - Chinese (Traditional) - Chokwe - Crimean Tatar - Croatian - Czech - Danish - Dari - Dimli - Dinka, Southwestern - Dutch - Dyula - Dzongkha - English - Esperanto - Estonian - Ewe - Faroese - Fijian - Finnish - Fon - French - Friulian - Galician - Ganda - Georgian - German - Greek - Guarani - Gujarati - Haitian - Halh Mongolian - Hausa - Hebrew - Hindi - Hungarian - Icelandic - Igbo - Iloko - Indonesian - Irish - Italian - Japanese - Javanese - Jingpho - Kabiyè - Kabuverdianu - Kabyle - Kamba - Kannada - Kanuri, Central (Latin script) - Kashmiri (Arabic script) - Kashmiri (Devanagari script) - Kazakh - Khmer - Kikuyu - Kimbundu - Kinyarwanda - Kongo - Korean - Kurdish, Central - Kurdish, Northern - Kyrgyz - Lao - Latgalian - Latin - Latvian - Ligurian - Limburgish - Lingala - Lithuanian - Lombard - Luba-Kasai - Luo - Luxembourgish - Macedonian - Magahi - Maithili - Malagasy - Malay - Malayalam - Maltese - Manipuri - Maori - Marathi - Minangkabau - Mizo - Marathi - Minangkabau - Mizo - Mongolian (Traditional) - Mossi - Myanmar (Burmese) - Nepali - Nigerian Fulfulde - Norwegian Bokmål - Norwegian Nynorsk - Nuer - Nyanja - Occitan - Oriya - Oromo, West Central - Pangasinan - Papiamento - Pashto, Southern - Pastho - Persian, Western - Plateau Malagasy - Polish - Portuguese (Brazilian) - Portuguese (European) - Punjabi - Romanian - Rundi - Russian - Samoan - Sango - Sanskrit - Santali - Sardinian - Scots Gaelic - Serbian (Cyrillic) - Serbian (Latin) - Shan - Shona - Sicilian - Silesian - Sindhi - Sinhala (Sinhalese) - Slovak - Slovenian - Somali - Northern Sotho - Southern Sotho - Spanish - Spanish (Latin America) - Standard Latvian - Standard Malay - Sundanese - Swahili - Swati - Swedish - Tagalog - Tajik - Tamasheq - Tamazight, Central Atlas - Tamil - Tatar - Telugu - Thai - Tibetan - Tigrinya - Tok Pisin - Tosk Albanian - Tsonga - Tswana - Tumbuka - Turkish - Turkmen - Twi - Ukrainian - Umbundu - Urdu - Uyghur - Uzbek, Northern - Venetian - Vietnamese - Waray (Philippines) - Welsh - Wolof - Xhosa - x - Yoruba - Zulu - LimitationsThe following list comprises the languages for which we recommend using our solution.
A
aceafaksqamarhyasastawaquyayrazaziazbB
banbmbjnbabebembnbhobsbugbgC
cacebhnezh-CNzh-TWcjkcrhhrcsD
daprsdiqdiknldyudzE
eneoeteeF
fofjfifonfrfurG
gllgkadeelgnguH
htkhkhahebjnhuI
isigiloidgaitJ
jajvkacK
kbpkeakabkamknknckaskskkkmkikmbrwkgkockbkmrkyL
loltglalvlijlilnltlmolualuolbM
mkmagmaimgmsmlmtmnimimrminlusmrminlusmnmosmyN
nefuvnbnnnusnyO
ocorgazP
pagpappbtpspespltplpt-BRpt-PTpaR
rornruS
smsgsasatcsgdsr-Cyrlsr-Latnshnsnscnszlsdsiskslsonsostes-ESes-419lvszsmsuswsssvT
tltgtaqtzmtatttethbotitpialststntumtrtktwU
ukumburuguznV
vecviW
warcywoX
xhY
xyoZ
zu
• T-LM has the same limitation as GPT-4 in English.
• Using English as a pivot language, T-LM is unable to answer questions that require a specific understanding of a country's culture.
• The performance of T-LM on the MMLU benchmark may not be representative of performance in other domains or tasks.
Get in touch.
We are here to answer your questions, and help you get what you want.